On the Popularity of Certain Numbers.
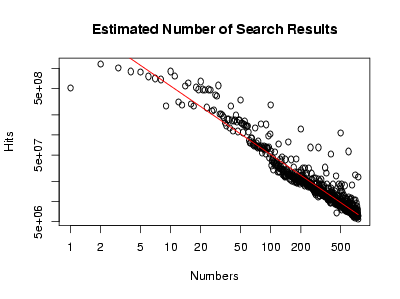
I searched for each number between 1 and 500 on Google, and recorded the (estimated) number of hits. I’m not aware of anyone having done this before; in any case, I made a chart:

Click on the above chart to see a bigger version. You can also look more closely at the first hundred numbers, or look at the above data with a log scale on the y-axis.
I have some observations and questions:
- There’s some periodicity in the above data (every 5, every 10, every 100).
- Can you explain how quickly the distribution falls off (is it exponentially decaying, for instance)?
- The most popular numbers are, in decreasing order of popularity: 2, 3, 10, 4, 5, 11, 6, 7, 8, 20, 15, 30, 14, 18, 1, 24, 21, 19, 25, 22, 28, 29, 50, and so on.
- The most popular numbers ending in 0 are, in decreasing order of popularity and having been divided by ten: 1, 2, 3, 5, 10, 4, 8, 9, 7, 20, 6, 50, 15, 12, 30, 25, 11, 40, 13, 18, 16, 14, and so on. Is the distribution of numbers ending in 0 related to the distribution of all numbers?
- Are certain families of numbers more popular? Are prime numbers or square numbers particularly popular?
You can download my comma-separated data file if you would like to play with the data yourself. Note, however, that I got this data from Google’s SOAP interface, which, for reasons I don’t understand, doesn’t give the same number of “estimated hits” as the web page interface.
Posted: Sunday, December 3, 2006 6:36:47am
Category: Personal
Permalink and Comments
{kind=link}
{kind=link}